Contenido
Introducción
Los archivos de audio digital se dividen en dos categorías principales: formatos sin pérdida y formatos con compresión con pérdida. Cada categoría tiene implicaciones específicas en la calidad del audio y en la aplicabilidad de técnicas como la esteganografía.
Los formatos sin pérdida pueden ser formatos que comprimen la información o formatos que no la comprimen. Pero en caso de hacerlo, realizan una compresión sin pérdida de información. Los formatos de compresión sin pérdida reducen el tamaño del archivo sin eliminar información de la señal de audio, permitiendo una reproducción exacta del original. Ejemplos destacados de estos formatos son FLAC (Free Lossless Audio Codec), WAV (Waveform Audio File Format) y ALAC (Apple Lossless Audio Codec). Estos formatos son ideales para aplicaciones profesionales de edición de audio, producción musical y almacenamiento de grabaciones de alta fidelidad, donde la integridad de la señal es fundamental.
Por otro lado, los formatos con compresión con pérdida utilizan algoritmos que eliminan partes de la señal de audio consideradas menos perceptibles para el oído humano, logrando una reducción significativa del tamaño del archivo. Sin embargo, esta compresión es irreversible y puede afectar la calidad del sonido, especialmente a tasas de bits bajas. Los formatos más comunes en esta categoría son MP3 (MPEG-1 Audio Layer 3), AAC (Advanced Audio Codec) y OGG Vorbis. Estos formatos son ampliamente utilizados en la distribución de música en línea, servicios de streaming y dispositivos portátiles debido a su eficiencia en la compresión.
La esteganografía en audio consiste en ocultar información dentro de archivos de sonido de manera que sea imperceptible para el oyente. La elección del formato de audio es crucial para la eficacia de las técnicas esteganográficas. Los formatos sin pérdida son más adecuados para la esteganografía, ya que mantienen la integridad de la señal de audio. Al no eliminar información durante la compresión, las modificaciones realizadas para ocultar datos permanecen intactas, permitiendo una recuperación precisa de la información oculta. Por ejemplo, en archivos WAV, es común utilizar una técnica basada en el Least Significant Bit (LSB), como el LSB replacement o el LSB matching que hemos estudiado en Técnicas de incrustación, que permite modificar las muestras de audio para insertar datos sin afectar perceptiblemente la calidad del sonido.
En contraste, la esteganografía en formatos con pérdida, como MP3, es más compleja debido a que el proceso de compresión elimina información de la señal de audio, lo que puede destruir o alterar los datos ocultos. Aunque existen técnicas avanzadas que buscan adaptarse a las características de estos formatos, es difícil usarlas en Python, dado que no existen librerías de bajo nivel que permitan acceder y modificar los datos necesarios.
Al seleccionar un formato de audio para aplicaciones esteganográficas, es fundamental considerar el equilibrio entre la calidad del sonido, el tamaño del archivo y la robustez de la técnica de ocultación. Los formatos sin pérdida ofrecen un entorno más seguro para la esteganografía, mientras que los formatos con pérdida presentan mayores desafíos para mantener la integridad de la información oculta.
En los siguientes apartados, exploraremos diversas técnicas para la inserción de información en estos formatos y analizaremos sus ventajas y limitaciones.
Digitalización de sonido
El sonido es una vibración mecánica que se propaga a través de un medio elástico, como el aire, el agua o los sólidos. Se genera cuando un objeto vibra y transmite esta vibración a las moléculas circundantes, creando una onda de presión que se desplaza en el medio. A diferencia de las ondas electromagnéticas, el sonido requiere un medio material para su transmisión; por ello, no puede viajar en el vacío. Su velocidad de propagación varía según el medio: en el aire a temperatura ambiente (~20°C) se desplaza a aproximadamente 343 m/s, mientras que en el agua puede alcanzar los 1500 m/s y en sólidos como el acero superar los 5000 m/s.
Desde un punto de vista físico, el sonido se compone de ondas longitudinales en las que las moléculas del medio oscilan en la misma dirección en la que se propaga la onda. Estas ondas presentan regiones alternas de compresión y rarefacción, lo que da lugar a fluctuaciones de presión que pueden ser captadas por nuestro sistema auditivo. La frecuencia de estas oscilaciones determina el tono del sonido, con frecuencias bajas generando sonidos graves y frecuencias altas produciendo sonidos agudos. El oído humano es capaz de percibir frecuencias entre aproximadamente 20 Hz y 20 kHz, aunque esta capacidad disminuye con la edad.
Otro aspecto fundamental del sonido es su amplitud, que se relaciona con la intensidad o volumen percibido. Se mide en decibelios (dB) y representa la magnitud de las variaciones de presión en la onda sonora. Un susurro puede estar en torno a 30 dB, mientras que el ruido de un motor de avión puede superar los 120 dB, nivel en el que el sonido puede causar daño auditivo. Además de la frecuencia y la amplitud, la fase de una onda sonora define su posición relativa en el tiempo y es un factor clave en la síntesis de sonido y en el procesamiento de señales de audio.
La percepción del sonido en los seres humanos depende del sistema auditivo, compuesto por tres partes principales: el oído externo, el oído medio y el oído interno. El oído externo capta las ondas sonoras y las dirige hacia el tímpano, que vibra en respuesta a estas. Estas vibraciones son amplificadas por la cadena de huesecillos en el oído medio (martillo, yunque y estribo) y posteriormente transmitidas al oído interno. Allí, en la cóclea, las vibraciones se convierten en impulsos eléctricos mediante células especializadas llamadas células ciliadas. Estos impulsos son enviados al cerebro a través del nervio auditivo, donde se interpretan como sonidos.
El sonido es, por tanto, un fenómeno físico con propiedades bien definidas, cuya percepción depende tanto de su estructura como de la capacidad del oído humano para captarlo y procesarlo. Su estudio es fundamental para comprender cómo se digitaliza el sonido.
La digitalización del sonido es el proceso mediante el cual una señal acústica continua se convierte en una secuencia de valores numéricos discretos. Este proceso es fundamental para el almacenamiento, transmisión y manipulación del sonido en sistemas digitales. A diferencia de una señal analógica, que varía de manera continua en el tiempo y la amplitud, una señal digital es una aproximación cuantificada en la que el sonido se representa como una serie de muestras numéricas tomadas en intervalos regulares.
Para digitalizar el sonido, se emplea un proceso conocido como modulación por impulsos codificados (PCM, Pulse Code Modulation), en el que se capturan valores discretos de la señal a una determinada frecuencia de muestreo y con una profundidad de bits específica. La frecuencia de muestreo determina cuántas veces por segundo se toman muestras de la señal y se expresa en Hertz (Hz). Según el teorema de Nyquist-Shannon, para reconstruir fielmente una señal analógica sin pérdida de información, la frecuencia de muestreo debe ser al menos el doble de la frecuencia más alta presente en la señal original. En aplicaciones de audio, una frecuencia de 44.1 kHz es común en formatos como WAV y CD-Audio, mientras que en grabaciones de alta fidelidad se emplean frecuencias de 48 kHz, 96 kHz o incluso 192 kHz.
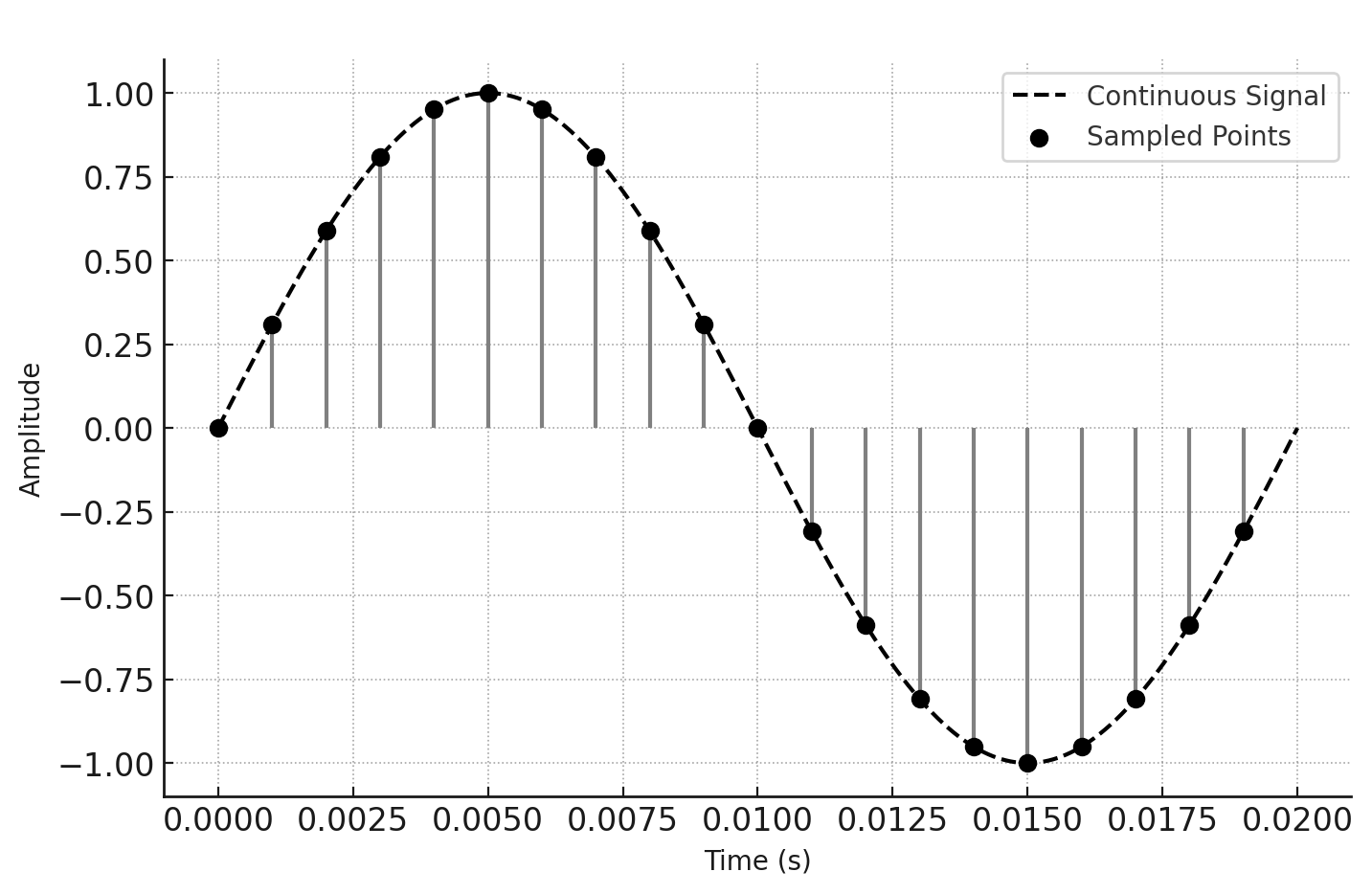
Además de la frecuencia de muestreo, otro factor crucial en la digitalización del sonido es la profundidad de bits, que determina el número de niveles de cuantización posibles para representar la amplitud de la señal. En un sistema de 16 bits, por ejemplo, cada muestra puede tomar uno de $2^{16}$ valores distintos, mientras que en un sistema de 24 bits, utilizado en estudios de grabación profesional, el número de niveles asciende a más de $2^{24}$. Una mayor profundidad de bits permite un rango dinámico más amplio y una menor distorsión en la representación del sonido.
El formato WAV (Waveform Audio File Format) es uno de los formatos más utilizados para almacenar sonido digital en su forma más pura. Desarrollado por Microsoft e IBM, WAV se basa en el esquema PCM, lo que significa que las muestras de audio se almacenan directamente sin compresión, preservando la fidelidad del sonido original. Debido a su estructura, los archivos WAV pueden ser grandes en comparación con otros formatos comprimidos, pero ofrecen ventajas en entornos donde la calidad del sonido es prioritaria, como en la producción musical, la edición de audio y el procesamiento de señales.
En un archivo WAV, la información del audio se organiza en forma de bloques de datos que contienen las muestras de sonido junto con metadatos sobre la estructura del archivo, como la frecuencia de muestreo, la profundidad de bits y el número de canales (mono o estéreo). Dado que WAV es un contenedor flexible, también puede almacenar audio comprimido utilizando códecs como ADPCM, aunque su uso principal sigue siendo el almacenamiento de audio PCM sin comprimir.
Gracias a su capacidad para representar el sonido con alta precisión, el formato WAV ha sido ampliamente adoptado en aplicaciones donde la fidelidad es fundamental. Sin embargo, en contextos donde el almacenamiento o la transmisión de audio requieren una reducción de tamaño, formatos como MP3 o AAC son más adecuados. La elección del formato de audio depende, por lo tanto, del equilibrio entre calidad, tamaño y propósito de uso.
La evolución de los formatos de audio digital ha permitido avances significativos en la accesibilidad y distribución del sonido. Mientras que los formatos comprimidos han facilitado la transmisión eficiente de audio a través de internet y dispositivos móviles, los formatos sin compresión como WAV siguen desempeñando un papel crucial en la producción y el análisis de audio de alta calidad. Comprender cómo se digitaliza y almacena el sonido es esencial para la manipulación eficiente de archivos de audio en cualquier aplicación digital.
El formato se basa en la estructura de archivos RIFF (Resource Interchange File Format), lo que significa que su contenido está organizado en bloques o chunks de datos. Su uso más común es el almacenamiento de audio en formato PCM (Pulse Code Modulation), que representa directamente las muestras de sonido digitalizadas sin compresión ni pérdida de calidad.
Un archivo WAV consta de tres secciones principales: la cabecera RIFF, el bloque fmt y el bloque de datos (data). Cada una de estas secciones contiene información esencial sobre el archivo y cómo interpretar sus muestras de audio.
La cabecera RIFF es el primer bloque del archivo y tiene un tamaño fijo de 44 bytes cuando se utiliza audio PCM sin metadatos adicionales. Se compone de los siguientes campos:
- Identificador RIFF (4 bytes): Contiene la cadena “RIFF” que indica que el archivo sigue la estructura RIFF.
- Tamaño del archivo (4 bytes): Representa el tamaño total del archivo en bytes, excluyendo los 8 bytes iniciales de la cabecera.
- Identificador de formato (4 bytes): Contiene la cadena “WAVE”, que indica que el archivo es de tipo WAV.
A continuación, se encuentra el bloque fmt, que almacena información sobre el formato de audio. Este bloque tiene al menos 16 bytes en su versión estándar y contiene los siguientes campos:
- Identificador de bloque (4 bytes): Contiene la cadena “fmt ” (con un espacio al final).
- Tamaño del bloque (4 bytes): Especifica el tamaño del bloque, que normalmente es 16 bytes para PCM.
- Formato de audio (2 bytes): Indica el tipo de codificación de audio. El valor 1 representa PCM sin compresión.
- Número de canales (2 bytes): Indica si el audio es mono (1) o estéreo (2).
- Frecuencia de muestreo (4 bytes): Representa la tasa de muestreo en Hz, por ejemplo, 44,100 Hz para audio CD.
- Tasa de bits (byte rate, 4 bytes): Representa la cantidad de bytes procesados por segundo y se calcula mediante la siguiente ecuación:
donde:
- $B$ es la tasa de bits (byte rate), medida en bytes por segundo.
- $f_s$ es la frecuencia de muestreo, medida en Hertz (Hz), que indica cuántas muestras por segundo se toman de la señal de audio.
- $C$ es el número de canales de audio (1 para mono, 2 para estéreo, etc.).
-
$D$ es la profundidad de bits (bit depth), que representa el número de bits utilizados para almacenar cada muestra de audio.
- Alineación de bloque (2 bytes): Representa el número de bytes por muestra en cada canal.
- Profundidad de bits (2 bytes): Indica la resolución de cada muestra de audio, generalmente 16 o 24 bits.
Después de la cabecera y del bloque fmt, el archivo contiene el bloque data, donde se almacenan las muestras de audio. Este bloque tiene la siguiente estructura:
- Identificador de bloque (4 bytes): Contiene la cadena “data”.
- Tamaño de los datos (4 bytes): Indica el número total de bytes en esta sección.
- Muestras de audio: Cada muestra se almacena en formato PCM, con un tamaño que depende de la profundidad de bits. Por ejemplo, en audio de 16 bits, cada muestra ocupa 2 bytes, y en audio de 24 bits, cada muestra ocupa 3 bytes. En archivos estéreo, las muestras de los canales izquierdo y derecho se almacenan de manera intercalada.
Las muestras PCM se almacenan en orden de bytes little-endian, lo que significa que el byte menos significativo se guarda primero. Esto es una característica común en sistemas que siguen la arquitectura de procesadores Intel.
A pesar de su antigüedad, el formato WAV sigue siendo un estándar en la industria del audio debido a su sencillez y fiabilidad. Su compatibilidad con distintos sistemas y su capacidad para almacenar audio sin pérdidas lo hacen ideal para el procesamiento digital de señales y la implementación de técnicas avanzadas como la esteganografía en audio.
El siguiente ejemplo muestra cómo leer un archivo de audio en formato WAV y extraer su información básica, incluyendo el número de canales, el tamaño de muestra y la cantidad total de muestras. Dependiendo de la profundidad de bits del archivo, el código selecciona el tipo de dato adecuado para interpretar las muestras de audio correctamente.
Dado que NumPy no admite un tipo de dato de 24 bits de manera nativa, cuando el archivo tiene un tamaño de muestra de 3 bytes, es necesario reconstruir manualmente los valores en enteros de 32 bits con signo (int32). Para ello, se implementa la función convert_ui24_to_i32, que toma los datos en crudo de 24 bits y los transforma correctamente a un formato de 32 bits, ajustando el bit de signo cuando es necesario.
El código también se asegura de manejar archivos de 8, 16 y 32 bits correctamente, utilizando los tipos de datos apropiados en NumPy. A continuación, se presenta el ejemplo completo:
import wave
import numpy as np
def convert_ui24_to_i32(audio_data):
audio_data = audio_data.reshape(-1, 3)
int32_data = (audio_data[:, 0].astype(np.int32) |
(audio_data[:, 1].astype(np.int32) << 8) |
(audio_data[:, 2].astype(np.int32) << 16))
int32_data[int32_data > 0x7FFFFF] -= 0x1000000
return int32_data
wav_filename = "audio.wav"
wav_file = wave.open(wav_filename)
num_channels = wav_file.getnchannels() #1=mono, 2=stereo
sample_width = wav_file.getsampwidth()
num_frames = wav_file.getnframes()
print(f"channels: {num_channels}")
print(f"sample width: {sample_width}")
print(f"num frames: {num_frames}")
raw_data = wav_file.readframes(num_frames)
if sample_width == 1:
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = audio_data.astype(np.int16) - 128
elif sample_width == 2:
audio_data = np.frombuffer(raw_data, dtype='<i2')
elif sample_width == 3:
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = convert_ui24_to_i32(audio_data)
elif sample_width == 4:
audio_data = np.frombuffer(raw_data, dtype='<i4')
else:
raise ValueError("Wrong format")
print(audio_data.shape, audio_data.dtype)
La salida obtenida para un archivo de ejemplo es la siguiente:
channels: 2
sample width: 3
num frames: 1605888
(3211776,) uint16
En el código anterior podemos ver el número de frames. Un frame (cuadro de muestras) es un conjunto de muestras que corresponden al mismo instante de tiempo en todos los canales del audio. La relación entre frame y sample depende del número de canales:
- En audio mono (1 canal), un frame y un sample son equivalentes.
- En audio estéreo (2 canales), un frame contiene dos samples (uno por canal).
- En audio multicanal un frame contiene un sample por cada canal de audio.
Por ejemplo, en un archivo WAV estéreo con 16 bits de profundidad por canal, cada sample ocupa 2 bytes y cada frame ocupa 4 bytes (2 canales $\times$ 2 bytes por sample). Por lo tanto, al procesar archivos de audio digital, es importante diferenciar entre frames y samples, especialmente cuando se trabaja con audio multicanal.
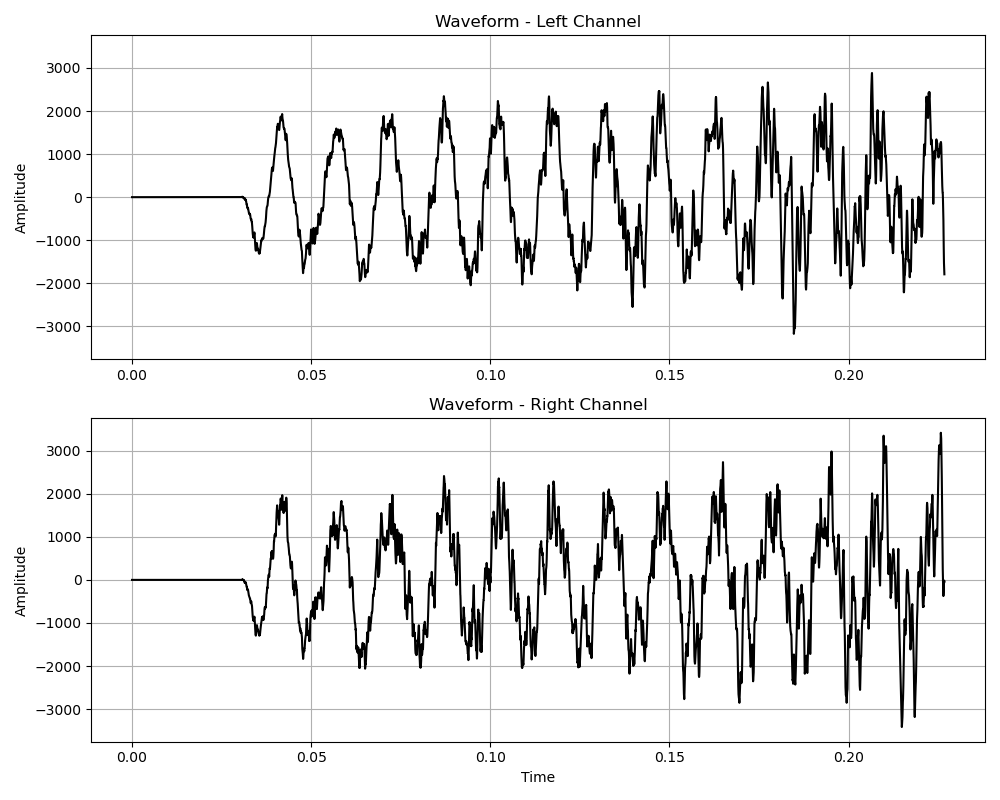
Ahora que podemos leer el archivo de audio, puede ser interesante representarlo gráficamente. Para ello solo tenemos que añadir este código Python:
import matplotlib.pyplot as plt
if num_channels == 2:
audio_data = audio_data.reshape(-1, 2)
audio_data_left = audio_data[:, 0]
audio_data_right = audio_data[:, 1]
else:
audio_data_left = audio_data
audio_data_right = None
start_sample = 0
end_sample = min(10000, len(audio_data_left))
frame_rate = wav_file.getframerate() if 'frame_rate' in globals() else 44100
time_axis = np.linspace(0, end_sample / frame_rate, end_sample)
fig, axes = plt.subplots(2, 1, figsize=(10, 6), sharey=True)
axes[0].plot(time_axis,
audio_data_left[start_sample:end_sample])
axes[0].set_ylabel("Amplitude")
axes[0].set_title("Waveform - Left Channel")
axes[0].grid()
if num_channels == 2:
axes[1].plot(time_axis,
audio_data_right[start_sample:end_sample])
axes[1].set_ylabel("Amplitude")
axes[1].set_title("Waveform - Right Channel")
axes[1].grid()
else:
fig.delaxes(axes[1])
plt.xlabel("Time")
plt.tight_layout()
plt.show()
De esta manera obtendremos una gráfica como la de la figura 2.
Incrustación de datos en audio
Introducción
La esteganografía en audio sin pérdida se basa en la modificación directa de los valores de las muestras de audio, en formatos que no aplican compresión con pérdida que degrade la señal original. Este enfoque permite ocultar información sin tener que preocuparse de la pérdida del mensaje incrustado por culpa de la compresión con pérdida.
El formato WAV, debido a su almacenamiento en PCM sin compresión, es una opción especialmente adecuada para la esteganografía en audio sin pérdida. Cada muestra de audio se almacena con una profundidad de bits específica (por ejemplo, 16 o 24 bits), lo que permite modificar los valores de forma precisa sin generar artefactos audibles.
En el ejemplo anterior hemos visto cómo leer la información de un archivo WAV, pero para usar esteganografía tenemos además que modificar las muestras y guardarlo de nuevo. Vamos a empezar viendo un ejemplo completo de cómo realizar este proceso.
import wave
import numpy as np
def convert_ui24_to_i32(audio_data):
audio_data = audio_data.reshape(-1, 3)
int32_data = (audio_data[:, 0].astype(np.int32) |
(audio_data[:, 1].astype(np.int32) << 8) |
(audio_data[:, 2].astype(np.int32) << 16))
int32_data[int32_data > 0x7FFFFF] -= 0x1000000
return int32_data
def convert_i32_to_ui24(audio_data):
audio_data = np.clip(audio_data, -8388608, 8388607)
uint24_data = np.zeros((len(audio_data), 3),
dtype=np.uint8)
uint24_data[:, 0] = audio_data & 0xFF
uint24_data[:, 1] = (audio_data >> 8) & 0xFF
uint24_data[:, 2] = (audio_data >> 16) & 0xFF
return uint24_data.flatten()
wav_filename = "audio.wav"
wav_file = wave.open(wav_filename, 'rb')
num_channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
frame_rate = wav_file.getframerate()
num_frames = wav_file.getnframes()
print(f"channels: {num_channels}")
print(f"sample width: {sample_width} bytes")
print(f"num frames: {num_frames}")
raw_data = wav_file.readframes(num_frames)
wav_file.close()
if sample_width == 1:
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = audio_data.astype(np.int16) - 128
elif sample_width == 2:
audio_data = np.frombuffer(raw_data, dtype='<i2')
elif sample_width == 3:
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = convert_ui24_to_i32(audio_data)
elif sample_width == 4:
audio_data = np.frombuffer(raw_data, dtype='<i4')
else:
raise ValueError("Wrong format")
audio_data = audio_data.copy()
audio_data[0] += 1
if sample_width == 1:
raw_data_modified = \
(audio_data + 128).astype(np.uint8).tobytes()
elif sample_width == 2:
raw_data_modified = audio_data.astype('<i2').tobytes()
elif sample_width == 3:
raw_data_modified = convert_i32_to_ui24(audio_data).tobytes()
elif sample_width == 4:
raw_data_modified = audio_data.astype('<i4').tobytes()
else:
raise ValueError("Wrong format")
output_filename = "audio_stego.wav"
with wave.open(output_filename, 'wb') as output_wav:
output_wav.setnchannels(num_channels)
output_wav.setsampwidth(sample_width)
output_wav.setframerate(frame_rate)
output_wav.writeframes(raw_data_modified)
Es conveniente tener en cuenta que en un archivo WAV, los datos de audio se almacenan en un formato intercalado cuando hay más de un canal. Esto significa que las muestras de cada canal se alternan en el flujo de datos, en lugar de almacenarse por separado. La estructura más común es el formato stereo (dos canales), en el cual las muestras del canal izquierdo y derecho se intercalan en cada ciclo de muestreo.
Para un archivo estéreo, la disposición de las muestras en la secuencia de datos sigue el siguiente patrón:
[sample_0_left, sample_0_right, sample_1_left, sample_1_right, sample_2_left, sample_2_right ...]
Esto significa que cada par de muestras representa el mismo instante de tiempo en el audio, con una muestra correspondiente a cada canal.
Cuando se carga un archivo WAV estéreo en un array de NumPy, la estructura de datos original es un vector plano con todas las muestras consecutivas. Para facilitar el procesamiento de cada canal por separado, se puede reorganizar en una matriz de forma $(N, 2)$, donde $N$ es el número de muestras y cada fila contiene una tupla con el valor del canal izquierdo y derecho:
\[\text{audio\_data} = \begin{bmatrix} L_0 & R_0 \\ L_1 & R_1 \\ L_2 & R_2 \\ \vdots & \vdots \end{bmatrix}\]Este formato permite realizar modificaciones en un canal sin afectar el otro, por ejemplo, reduciendo la amplitud del canal izquierdo sin alterar el derecho.
Antes de guardar de nuevo en un archivo WAV, deben reestructurarse en un formato plano antes de escribirlos. Esto se logra con una operación de reshape inversa en NumPy, asegurando que las muestras de cada canal vuelvan a intercalarse correctamente.
Esto podría hacerse de la siguiente manera. Para reorganizar los datos en caso de ser una audio estéreo:
if num_channels == 2:
audio_data = audio_data.reshape(-1, 2)
Para volver al formato plano antes de guardar:
if num_channels == 2:
audio_data = audio_data.reshape(-1)
Sin embargo, estas operaciones no son estrictamente necesarias para realizar esteganografía. Dependerá del método que se quiera usar a la hora de incrustar datos y de cómo quiere hacerse.
LSB matching
En Técnicas de incrustación: Incrustación de bits en el LSB, se ha explicado el método de LSB matching como una técnica para modificar los bits menos significativos de un conjunto de valores con el fin de ocultar información. En este apartado, aplicaremos este método para incrustar datos dentro de un archivo de audio digital en formato WAV.
En un archivo de audio digital, la señal sonora se representa mediante una secuencia de muestras discretas, donde cada muestra es un valor entero que indica la amplitud de la señal en un instante de tiempo determinado. Estas muestras pueden almacenarse con diferentes profundidades de bits, siendo las más comunes 8, 16, 24 o 32 bits por muestra. La técnica de LSB matching se basa en modificar el bit menos significativo de estas muestras para codificar la información deseada. Si el bit menos significativo de una muestra no coincide con el bit que queremos incrustar, se suma o resta una unidad de forma aleatoria.
El siguiente código en Python muestra cómo implementar LSB matching para ocultar un mensaje dentro de un archivo de audio digital.
Primero convertimos el mensaje en una secuencia de bits utilizando su representación en código binario. Luego, iteramos sobre las muestras de audio y modificamos aleatoriamente el bit menos significativo de una muestra para almacenar cada bit del mensaje.
Nótese que la función lsb_matching_audio nunca realiza operaciones de suma $+1$ sobre muestras con el valor máximo permitido por su profundidad de bits, ni operaciones de resta $-1$ sobre muestras con el valor mínimo. Esto se debe a que el rango de valores de cada muestra está limitado por su tipo de datos: en audio de 16 bits, por ejemplo, las muestras están representadas como valores enteros en el rango de $-32768$ a $32767$. Sumar $1$ a una muestra con el valor máximo provocaría un overflow, resultando en un cambio drástico en la señal que podría ser detectable mediante análisis estadísticos o incluso perceptible al oído.
Por esta razón, cualquier modificación de los bits menos significativos debe realizarse con precaución para minimizar el impacto en la calidad del audio y evitar artefactos audibles.
A continuación podemos ver un ejemplo en Python en el que incrustamos información usando LSB matching. En el ejemplo se usan las funciones anteriores convert_ui24_to_i32 y convert_i32_to_ui24 que no se incluyen de nuevo. En el ejemplo se descompone el mensaje en bits y a continuación se incrusta un bit en cada muestra de audio. Nótese el uso de un máximo y un mínimo en la función lsb_matching para no producir overflows.
import random
import wave
import numpy as np
def lsb_matching(value, bit, mx=255, mn=0):
if value % 2 == bit:
return value
if value == mx:
s = -1
elif value == mn:
s = +1
else:
s = random.choice([-1, 1])
return value + s
# < convert_ui24_to_i32 and convert_i32_to_ui24 code
def embed(wav_filename_in, wav_filename_out, message):
wav_file = wave.open(wav_filename_in, 'rb')
num_channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
frame_rate = wav_file.getframerate()
num_frames = wav_file.getnframes()
raw_data = wav_file.readframes(num_frames)
wav_file.close()
if sample_width == 1:
mx, mn = 127, -128
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = audio_data.astype(np.int16) - 128
elif sample_width == 2:
mx, mn = 32767, -32768
audio_data = np.frombuffer(raw_data, dtype='<i2')
elif sample_width == 3:
mx, mn = 8388607, -8388608
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = convert_ui24_to_i32(audio_data)
elif sample_width == 4:
mx, mn = 2147483647, -2147483648
audio_data = np.frombuffer(raw_data, dtype='<i4')
else:
raise ValueError("Wrong format")
audio_data = audio_data.copy()
message_bits = ''.join(format(ord(c), '08b') \
for c in message)
if len(message_bits) > len(audio_data):
raise ValueError("Message too long")
for i in range(0, len(message_bits)):
bit = int(message_bits[i])
audio_data[i] = \
lsb_matching(audio_data[i], bit, mx, mn)
if sample_width == 1:
raw_data_modified = \
(audio_data + 128).astype(np.uint8).tobytes()
elif sample_width == 2:
raw_data_modified = \
audio_data.astype('<i2').tobytes()
elif sample_width == 3:
raw_data_modified = \
convert_i32_to_ui24(audio_data).tobytes()
elif sample_width == 4:
raw_data_modified = \
audio_data.astype('<i4').tobytes()
else:
raise ValueError("Wrong format")
with wave.open(wav_filename_out, 'wb') as output_wav:
output_wav.setnchannels(num_channels)
output_wav.setsampwidth(sample_width)
output_wav.setframerate(frame_rate)
output_wav.writeframes(raw_data_modified)
message = "Hidden text"
embed("audio.wav", "audio_stego.wav", message)
A continuación, vemos el código para extraer el mensaje. El proceso es similar a la inversa, recorremos las muestras de audio y vamos extrayendo el LSB, para, finalmente, reconstruir el mensaje.
Para recuperar el mensaje incrustado en el audio, es necesario recorrer los píxeles en el mismo orden en que se realizó la incrustación y extraer el bit menos significativo del canal correspondiente. Luego, estos bits se agrupan en bloques de 8 para reconstruir los caracteres del mensaje original en código ASCII. El proceso finalizará cuando hayamos extraído todo el mensaje. Sin embargo, no hemos implementado ningún mecanismo para saber cuándo el mensaje ha sido extraído al completo, por lo que en el ejemplo hemos extraído $88$ bits, que es justo lo que necesitamos. Existen diferentes técnicas para lidiar con este problema, como por ejemplo introducir una cabecera al principio que nos diga la longitud del mensaje, o incrustar una marca de fin de mensaje. Lidiaremos con estos problemas más adelante.
import wave
import numpy as np
# < convert_ui24_to_i32 code
def extract(wav_filename_in, msglen):
wav_file = wave.open(wav_filename_in, 'rb')
num_channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
frame_rate = wav_file.getframerate()
num_frames = wav_file.getnframes()
raw_data = wav_file.readframes(num_frames)
wav_file.close()
if sample_width == 1:
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = audio_data.astype(np.int16) - 128
elif sample_width == 2:
audio_data = np.frombuffer(raw_data, dtype='<i2')
elif sample_width == 3:
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = convert_ui24_to_i32(audio_data)
elif sample_width == 4:
audio_data = np.frombuffer(raw_data, dtype='<i4')
else:
raise ValueError("Wrong format")
message_bits = []
for i in range(0, msglen):
bit = audio_data[i]%2
message_bits.append(bit)
message_bits = ''.join(map(str, message_bits))
message = ''.join(chr(int(message_bits[i:i+8], 2)) \
for i in range(0, len(message_bits), 8))
return message
message = extract("audio_stego.wav", 88)
print(message)
Matrix embedding
En el apartado indicado se ha explicado el método de matrix embedding como una técnica para incrustar más información con menos modificaciones. En este apartado, aplicaremos este método para incrustar datos dentro de un archivo de audio digital en formato WAV.
A continuación, se presenta un ejemplo en Python que usa matrix embedding en audio. El código mostrado utiliza las funciones de matrix embedding presentadas en el apartado indicado, así como la función de LSB matching descrita en el apartado anterior.
Inicialmente, se calcula la representación binaria del mensaje que se desea ocultar, almacenándolo en la variable message_bits. Se utiliza un código con $p=3$, por lo que en cada bloque de $2^p-1$ muestras de audio se pueden incrustar $3$ bits de mensaje. Para garantizar que la longitud del mensaje sea un múltiplo de $3$, se agregan ceros al final de la variable (padding).
A continuación, se recorren las muestras de audio, procesando los bloques de tamaño $2^p-1$. En cada bloque, se determina qué muestras deben modificarse para incrustar los $3$ bits de mensaje correspondientes, asegurando que el número de cambios sea mínimo. Una vez realizadas las modificaciones, se guarda el archivo de audio modificado en un nuevo archivo stego.
En el ejemplo se usan las funciones presentadas en apartados anteriores convert_ui24_to_i32 y convert_i32_to_ui24, que no se incluyen de nuevo.
import random
import wave
import numpy as np
P = 3
BLOCK_LEN = 2**P-1
M = np.array([
[0, 0, 0, 1, 1, 1, 1],
[0, 1, 1, 0, 0, 1, 1],
[1, 0, 1, 0, 1, 0, 1]
])
def lsb_matching(value, bit, mx=255, mn=0):
if value % 2 == bit:
return value
if value == mx:
s = -1
elif value == mn:
s = +1
else:
s = random.choice([-1, 1])
return value + s
def ME_embed(M, c, m):
s = c.copy()
col_to_find = (np.dot(M, c) - m) % 2
for position, v in enumerate(M.T):
if np.array_equal(v, col_to_find):
s[position] = (s[position] + 1) % 2
break
return s
# < convert_ui24_to_i32 and convert_i32_to_ui24 code
def embed(wav_filename_in, wav_filename_out, message):
wav_file = wave.open(wav_filename_in, 'rb')
num_channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
frame_rate = wav_file.getframerate()
num_frames = wav_file.getnframes()
raw_data = wav_file.readframes(num_frames)
wav_file.close()
if sample_width == 1:
mx, mn = 127, -128
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = audio_data.astype(np.int16) - 128
elif sample_width == 2:
mx, mn = 32767, -32768
audio_data = np.frombuffer(raw_data, dtype='<i2')
elif sample_width == 3:
mx, mn = 8388607, -8388608
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = convert_ui24_to_i32(audio_data)
elif sample_width == 4:
mx, mn = 2147483647, -2147483648
audio_data = np.frombuffer(raw_data, dtype='<i4')
else:
raise ValueError("Wrong format")
audio_data = audio_data.copy()
message_bits = [
int(bit) for byte in message.encode()
for bit in format(byte, '08b')
]
padding = (-len(message_bits)) % P
message_bits += [0] * padding
message_bits = np.array(message_bits)
if len(message_bits) > len(audio_data):
raise ValueError("Message too long")
num_blocks = len(message_bits)//3
j = 0
for i in range(0, num_blocks*BLOCK_LEN, BLOCK_LEN):
c = audio_data[i:i+BLOCK_LEN]%2
m = message_bits[j:j+P]
s = ME_embed(M, c, m)
dif_idx = np.flatnonzero(c != s)
if dif_idx.size>0:
audio_data[i+dif_idx] = \
lsb_matching(audio_data[i+dif_idx], s[dif_idx])
j += P
if sample_width == 1:
raw_data_modified = \
(audio_data + 128).astype(np.uint8).tobytes()
elif sample_width == 2:
raw_data_modified = \
audio_data.astype('<i2').tobytes()
elif sample_width == 3:
raw_data_modified = \
convert_i32_to_ui24(audio_data).tobytes()
elif sample_width == 4:
raw_data_modified = \
audio_data.astype('<i4').tobytes()
else:
raise ValueError("Wrong format")
with wave.open(wav_filename_out, 'wb') as output_wav:
output_wav.setnchannels(num_channels)
output_wav.setsampwidth(sample_width)
output_wav.setframerate(frame_rate)
output_wav.writeframes(raw_data_modified)
message = "Hidden text"
embed("audio.wav", "audio_stego.wav", message)
Para extraer el mensaje, tenemos que realizar justo la operación inversa. Igual que en el apartado anterior, no hemos establecido un mecanismo para saber cuándo el mensaje ha sido extraído al completo, por lo que en el ejemplo sacamos directamente los $88$ bits que sabemos que tiene el mensaje. Sin embargo, como también se comentó en el apartado anterior, la forma correcta de hacerlo sería usando una cabecera al principio que nos diga la longitud del mensaje, o incrustar una marca de fin de mensaje.
Así, el primer paso será convertir la longitud que sabemos que tiene el mensaje en un múltiplo de $3$, puesto que estamos usando $p=3$. A continuación, tendremos que recorrer las muestras de audio, de bloque en bloque, extrayendo los $3$ bits correspondientes a cada bloque y guardándolos en message_bits, para, finalmente, agruparlos y recuperar la codificación original.
import wave
import numpy as np
P = 3
BLOCK_LEN = 2**P-1
M = np.array([
[0, 0, 0, 1, 1, 1, 1],
[0, 1, 1, 0, 0, 1, 1],
[1, 0, 1, 0, 1, 0, 1]
])
def ME_extract(M, s):
return np.dot(M, s) % 2
# < convert_ui24_to_i32 code
def extract(wav_filename_in, msglen):
wav_file = wave.open(wav_filename_in, 'rb')
num_channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
frame_rate = wav_file.getframerate()
num_frames = wav_file.getnframes()
raw_data = wav_file.readframes(num_frames)
wav_file.close()
if sample_width == 1:
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = audio_data.astype(np.int16) - 128
elif sample_width == 2:
audio_data = np.frombuffer(raw_data, dtype='<i2')
elif sample_width == 3:
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = convert_ui24_to_i32(audio_data)
elif sample_width == 4:
audio_data = np.frombuffer(raw_data, dtype='<i4')
else:
raise ValueError("Wrong format")
l = msglen + (-msglen) % P
num_blocks = (l//3)
message_bits = []
for i in range(0, num_blocks*BLOCK_LEN, BLOCK_LEN):
s = audio_data[i:i+BLOCK_LEN]%2
m = ME_extract(M, s)
message_bits.extend(m.tolist())
message_bits = ''.join(map(str, message_bits))
message = ''.join(chr(int(message_bits[i:i+8], 2)) \
for i in range(0, len(message_bits), 8))
return message
message = extract("audio_stego.wav", 88)
print(message)
En este punto, es útil realizar algunos cálculos para comparar la eficiencia de la técnica matrix embedding frente al método tradicional de LSB matching en la ocultación de información dentro de archivos de audio. La tabla de eficiencia de matrix embedding muestra cómo varía la capacidad de incrustación relativa y la eficiencia en función del parámetro $p$, lo que nos servirá como base para estos cálculos.
Consideremos un archivo de audio estéreo con una frecuencia de muestreo de 44.1 kHz y una duración de 10 segundos. Esto significa que el número total de muestras en el archivo es de $44100 \times 10 \times 2 = 882000$. Si aplicamos LSB matching, podríamos insertar un bit por cada muestra, permitiendo ocultar hasta $882000$ bits. Sin embargo, para minimizar la detectabilidad del método e introducir menos distorsión, suponemos que solo se incrusta información en el 10\% de las muestras, lo que reduce la capacidad efectiva a $88200$ bits. Como en LSB matching aproximadamente la mitad de las muestras ya tienen el bit menos significativo en la posición correcta, se requeriría modificar alrededor de $44100$ muestras.
Si en lugar de LSB matching empleamos matrix embedding con $p=7$, el payload relativo es de $0.0551$. Esto implica que podemos ocultar aproximadamente $882000 \times 0.0551 = 48598$ bits. Además, la cantidad de modificaciones necesarias es mucho menor, reduciéndose a aproximadamente $882000 / (2^7-1) = 6944$ muestras alteradas. Como se observa, la cantidad de modificaciones para incrustar una cantidad similar de información disminuye drásticamente, pasando de $44100$ a $6944$ muestras, lo que hace que el mensaje sea más difícil de detectar. Esta ventaja se hace aún más evidente cuando la cantidad de información incrustada es menor.
Incrustación adaptativa
Introducción
En la sección previa, exploramos la técnica de LSB matching para ocultar información y cómo su eficiencia puede mejorarse mediante matrix embedding. Este método permite insertar una cantidad comparable de datos con un menor número de modificaciones, reduciendo así la probabilidad de detección. Como siguiente avance, es fundamental optimizar la elección de las áreas en las que se realiza la incrustación, priorizando aquellas donde la presencia de información oculta sea menos evidente.
En el caso del audio, la selección adecuada de las regiones donde se insertará la información es aún más crítica. A diferencia de las imágenes, donde la variabilidad en los valores de píxeles es alta incluso en zonas uniformes, los archivos de audio pueden contener segmentos de silencio absoluto, representados por largas secuencias de muestras con valores cero o cercanos a cero. Incrustar datos en estas regiones puede resultar problemático, ya que cualquier modificación en una zona de silencio absoluto puede ser fácilmente detectable.
Para evitar este problema, es fundamental utilizar una estrategia de incrustación adaptativa que evalúe la estructura de la señal y seleccione dinámicamente las áreas más adecuadas para la modificación. En particular, las regiones con mayor energía o complejidad espectral suelen ser más adecuadas para la inserción de datos, ya que las alteraciones quedan mejor camufladas dentro del contenido sonoro.
El desarrollo de los STC (Syndrome Trellis Codes) [Fil:2011:stc], introducido en Técnicas de incrustación: Cómo evitar zonas detectables, supuso un punto de inflexión en la esteganografía, estableciendo un nuevo enfoque para la inserción de información oculta. Estos códigos permiten separar el proceso esteganográfico en dos etapas independientes: la primera consiste en calcular un coste de modificación para cada píxel, mientras que la segunda se encarga de incrustar el mensaje minimizando el impacto total de los cambios.
En la fase inicial, el propósito es definir un criterio que cuantifique la probabilidad de detección de una alteración en un determinado píxel, asignándole un coste acorde a dicha susceptibilidad. La segunda etapa, en cambio, optimiza la incrustación del mensaje de manera que la suma de los costes de los píxeles modificados sea la mínima posible.
Como los STC se encargan de resolver la segunda fase, el diseño de un nuevo método esteganográfico basado en esta técnica se reduce a desarrollar una función eficaz para determinar el coste de modificación de cada píxel, lo que simplifica la creación de esquemas más sofisticados de ocultación de información.
Cálculo de costes
La mayoría de los métodos para calcular costes en esteganografía de audio son de carácter experimental y carecen de una fundamentación matemática rigurosa que indique con precisión en qué regiones de la señal es más seguro modificar muestras sin ser detectado. Debido a esta limitación, el enfoque más común consiste en probar distintas estrategias y validarlas mediante estegoanálisis, comparándolas con métodos ya existentes. Si una nueva función de coste dificulta la detección por parte de los algoritmos de estegoanálisis en comparación con las funciones previas, podríamos considerarla más efectiva.
Sin embargo, hay casos en los que la elección de las regiones de incrustación es clara. En particular, las secciones de silencio absoluto dentro de la señal deben evitarse, ya que cualquier modificación en estas zonas resulta altamente detectable debido a la ausencia total de variabilidad en la señal original. Fuera de estos casos evidentes, la optimización de la función de coste sigue siendo un desafío, ya que la percepción de alteraciones en el audio depende de factores como la energía de la señal, la presencia de transitorios y la sensibilidad del sistema auditivo humano.
Sin embargo, este proceso es complejo, ya que los resultados experimentales dependen en gran medida del conjunto de datos de audio utilizado. Si la base de datos no es lo suficientemente amplia y diversa, los resultados podrían no ser representativos, lo que llevaría a desarrollar funciones de coste que solo funcionan bien en un conjunto específico de señales, pero que no generalizan adecuadamente.
Este es un desafío que excede el alcance de este libro. No obstante, exploraremos cómo construir una función de coste de manera progresiva utilizando filtros, un enfoque ampliamente empleado en la disciplina.
Un filtro es una función matemática aplicada a una señal de audio para resaltar o atenuar ciertas características de sus muestras. En el contexto del cálculo de costes en esteganografía, los filtros se utilizan para analizar la estructura local de la señal y determinar en qué regiones la inserción de información es menos detectable.
Los filtros pueden diseñarse para capturar distintos aspectos de la señal de audio, como la presencia de transitorios, variaciones de amplitud o cambios en el contenido espectral. Por ejemplo, un filtro basado en la energía local puede ayudar a identificar zonas de silencio, donde una modificación resultaría más evidente, y diferenciarlas de áreas con alta energía o ruido, donde las alteraciones son menos perceptibles.
Existen diversos filtros utilizados en procesamiento de audio para analizar estructuras y patrones específicos. Entre ellos, los filtros de detección de transitorios, como los que analizan la derivada de la envolvente de la señal, permiten identificar cambios bruscos en el sonido, resaltando eventos de corta duración. Por otro lado, los filtros espectrales, como aquellos basados en la Transformada de Fourier o en bancos de filtros Mel, pueden resaltar la presencia de ciertas frecuencias, facilitando la identificación de regiones donde la inserción de información es más segura.
Desde un punto de vista matemático, un filtro suele representarse como una convolución entre la señal de audio y una ventana de análisis (kernel), que define la transformación aplicada a cada muestra en función de sus vecinas.
Empecemos con algo sencillo: ignorar las zonas de silencio. Si leemos las muestras de audio usando Python, podemos encontrar zonas de silencio como las siguiente:
>>> samples[0:100]
array([0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0], dtype=int16)
Si aplicamos una técnica de incrustación basada en LSB matching, obtendríamos algo como esto:
array([0, 0, 1,-1,-1,-1, 1,-1, 1, 0, 0, 0, 1,-1,-1, 1, 1,
1,-1, 1, 0,-1,-1, 1, 1, 0, 1,-1, 1, 0,-1, 1, 1, 0,
0, 1, 1,-1, 0, 0, 0,-1,-1, 1, 0, 1,-1,-1, 0, 1, 0,
-1, 0, 0, 0,-1, 0, 0, 1,-1,-1,-1,-1,-1,-1, 0, 0,-1,
1, 0, 0, 0, 0, 1, 0, 0, 0,-1, 1, 1, 1, 1,-1, 1,-1,
1, 1, 0, 1,-1, 0,-1, 1, 1, 1,-1,-1, 1, 1, 0],
dtype=int16)
Dado que las modificaciones en regiones de silencio o con valores cercanos a cero son las más fácilmente detectables en una señal de audio, comenzaremos diseñando una función de coste que penalice estas áreas. Para lograrlo, definiremos el coste como la inversa del valor absoluto de la muestra. De este modo, las muestras con valores bajos recibirán un coste elevado, mientras que aquellas con mayor amplitud tendrán un coste reducido.
Este enfoque garantiza que los STC prioricen la incrustación en regiones con amplitud significativa, evitando insertar datos en zonas de baja energía o cercanas a cero a menos que no haya otra alternativa. Así, se minimiza la probabilidad de detección, ya que las modificaciones quedan ocultas dentro de las variaciones naturales de la señal.
Definimos la función de coste $C(i)$ para una muestra de audio $x_i$ como:
\[C(i) = \frac{1}{|x_i| + \epsilon}\]donde:
- $C(i)$ representa el coste de modificar la muestra $x_i$.
- $|x_i|$ es el valor absoluto de la amplitud de la muestra de audio.
- $\epsilon$ es un valor pequeño positivo que se añade para evitar divisiones por cero cuando $x_i = 0$.
Esta función asigna un coste alto a las muestras con valores bajos y un coste bajo a las muestras con amplitudes más grandes.
Podemos escribir la función de cálculo de costes de la siguiente manera:
import numpy as np
def cost(audio_samples, epsilon=1e-20):
return 1 / (np.abs(audio_samples) + epsilon)
Esta función nos proporciona una forma sencilla de evitar las muestras de audio más detectables, e introduce una forma de incrustar información basada en incrustar primero en las amplitudes más altas. Otra forma de enfocar el problema consiste en incrustar primero en las zonas más complejas. Para ello podríamos usar filtros para determinar que zonas son más complejas. Una forma de hacerlo es usar un filtro derivativo [chen:2020:audio_derivative], que nos proporciona una función de coste como la siguiente:
\[C(i) = \frac{1}{|x_i| + |r_f| + \epsilon}\]donde:
- $x_i$ es el valor de la muestra de audio original.
-
$r_f$ es el residuo del filtro derivativo, obtenido al aplicar un filtro $f_n$ a la señal original:
\[r_f = f_n \otimes x_i\]siendo $\otimes$ la operación de convolución.
- $\epsilon$ es un valor pequeño positivo que se añade para evitar divisiones por cero.
Esta función de coste penaliza las modificaciones en muestras con baja amplitud y en regiones donde la señal varía poco, mientras que favorece la inserción de información en zonas con alta energía o transitorios, donde las modificaciones son menos perceptibles.
A continuación, podemos ver una implementación de la función de coste usando el filtro [-1, 2, 1]. El lector puede experimentar con otros filtros como [1, -3, 3, -1] o [-1, 4, -6, 4, -1], u otros filtros analizados en [chen:2020:audio_derivative].
import numpy as np
from scipy.signal import convolve
def cost(audio_samples, epsilon=1e-20):
f = np.array([-1, 2, 1])
r_f = convolve(audio_samples, f, mode='same')
cost = 1/(np.abs(audio_samples)+np.abs(r_f)+epsilon)
return cost
En el siguiente apartado veremos cómo usar esta función de coste para incrustar información usando los STC.
Syndrome Trellis Codes
En Técnicas de incrustación: Cómo evitar zonas detectables hemos visto cómo funcionan los Syndrome Trellis Codes y cómo usarlos a través de la librería pySTC. Por lo tanto, aplicarlos a audio es bastante directo. Basta con calcular los costes y llamar directamente a la librería para ocultar el mensaje. Usaremos la función de cálculo de costes [chen:2020:audio_derivative] presentada en el apartado anterior.
El siguiente código Python incrusta la información usando STC en el primer canal de audio. El código es similar al presentado en apartados anteriores, salvo por la incrustación usando STC, que se aplica tal y como se ha visto en Técnicas de incrustación: Cómo evitar zonas detectables.
El código de incrustación del mensaje es el siguiente:
import wave
import pystc
import numpy as np
from scipy.signal import convolve
# <cost function code>
# <convert_ui24_to_i32 code>
# <convert_i32_to_ui24 code>
def embed(wav_filename_in, wav_filename_out,
message, seed=32):
wav_file = wave.open(wav_filename_in, 'rb')
num_channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
frame_rate = wav_file.getframerate()
num_frames = wav_file.getnframes()
raw_data = wav_file.readframes(num_frames)
wav_file.close()
if sample_width == 1:
mx, mn = 127, -128
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = audio_data.astype(np.int16) - 128
elif sample_width == 2:
mx, mn = 32767, -32768
audio_data = np.frombuffer(raw_data, dtype='<i2')
elif sample_width == 3:
mx, mn = 8388607, -8388608
audio_data = np.frombuffer(raw_data, dtype=np.uint8)
audio_data = convert_ui24_to_i32(audio_data)
elif sample_width == 4:
mx, mn = 2147483647, -2147483648
audio_data = np.frombuffer(raw_data, dtype='<i4')
else:
raise ValueError("Wrong format")
audio_data = audio_data.copy()
if num_channels > 1:
audio_data = audio_data.reshape(-1, num_channels)
audio_data_ch1 = audio_data[:,0]
else:
audio_data_ch1 = audio_data
costs = cost(audio_data_ch1)
audio_data_ch1 = audio_data_ch1.reshape(-1,1)
audio_data_ch1 = pystc.hide(message.encode(),
audio_data_ch1, costs, costs, seed, mx, mn)
audio_data_ch1 = audio_data_ch1.reshape(-1)
if num_channels > 1:
audio_data[:,0] = audio_data_ch1
audio_data = audio_data.reshape(-1)
else:
audio_data = audio_data_ch1
if sample_width == 1:
raw_data_modified = \
(audio_data + 128).astype(np.uint8).tobytes()
elif sample_width == 2:
raw_data_modified = \
audio_data.astype('<i2').tobytes()
elif sample_width == 3:
raw_data_modified = \
convert_i32_to_ui24(audio_data).tobytes()
elif sample_width == 4:
raw_data_modified = \
audio_data.astype('<i4').tobytes()
else:
raise ValueError("Wrong format")
with wave.open(wav_filename_out, 'wb') as output_wav:
output_wav.setnchannels(num_channels)
output_wav.setsampwidth(sample_width)
output_wav.setframerate(frame_rate)
output_wav.writeframes(raw_data_modified)
seed = 32 # secret seed
message = "Hidden text"
embed("audio.wav", "audio_stego.wav", message, seed)
Actualmente no hay comentarios en este artículo.
Añade un comentario