En este artículo vamos a ver cómo incrustar información en imágenes y en audio usando el bit menos significativo (LSB) de cada byte.
Contenido
- Información en el bit menos significativo
- Dos técnicas habituales
- Incrustación de la información con LSB replacement
- Incrustación de la información con LSB matching
- Extracción de la información
- Los peligros del LSB replacement
- Hacia una incrustación más eficiente
- Esteganografía LSB en imágenes sin comprimir
- Esteganografía LSB en imágenes JPEG
- Esteganografía LSB en ficheros de audio WAV
Información en el bit menos significativo
El objetivo principal de la esteganografía es el de no ser detectado. Por lo tanto, siempre intentaremos modificar la información del medio en el que queremos ocultar un mensaje, de forma que dicha modificación pase desapercibida.
También nos interesará modificar valores que un estegoanalista no pueda predecir de forma sencilla. Puesto que si se puede deducir su valor original, bastará con compararlo con el valor del medio analizado para saber que ha sido alterado. O como mínimo, para lanzar fuertes sospechas sobre el uso de esteganografía.
Por ello, aquellos medios digitales formados por datos difíciles de modelar estadísticamente, son especialmente aptos para esconder información. Algunos medios de este tipo, de uso habitual en esteganografía, son las imágenes, el audio y el vídeo.
Incluso disponiendo de un medio formado por datos difíciles de modelar, conviene realizar las mínimas modificaciones posibles. Y la modificación mínima que podemos realizar sobre un byte es una modificación en una unidad.
Tomemos como ejemplo un byte de valor 160. Su representación en binario es la siguiente:
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
Se ha marcado en negrita el bit menos significativo (LSB), que en este caso tiene el valor 0. Es decir, que este byte, tiene incrustado un bit de mensaje de valor 0. Si este es el valor que queremos incrustar, no será necesario realizar ninguna operación. Pero si el valor del bit del mensaje que queremos incrustar es el 1, tendremos que realizar una operación sobre el valor del byte que cambie su LSB.
Dos técnicas habituales
Cuando se trata de incrustar información en el bit menos significativo de un byte existen dos técnicas habituales: el LSB replacement y el LSB matching. La primera de ellas y más frecuente es una técnica insegura, para la que existen múltiples ataques y que consiste, simplemente, en sustituir el valor del LSB por el valor del mensaje.
Continuando con el ejemplo anterior, para incrustar un 1 en un byte con valor 160:
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
Lo único que tendremos que hacer es sustituir el LSB por 1:
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
Esta técnica se conoce como LSB replacement y no se recomienda su uso por ser detectable. En el apartado “Los peligros del LSB replacement” se explica qué hace a esta técnica insegura.
Otra forma de modificar el LSB consisten sumar 1 o restar 1 al valor del byte. Por ejemplo, sumar 1 a:
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
Nos dará como resultado:
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
Mientras que al restar uno obtendremos:
| 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
En ambos casos hemos modificado el LSB, por lo que ambos casos llevan incrustado un 1 como valore del mensaje. El segundo caso, sin embargo, ha supuesto modificar 5 bits. Pero esto no debe considerarse más inseguro, puesto que en ambos casos hemos modificado el valor del byte en una unidad.
Esta técnica se conoce como LSB matching o incrustación ±1 y es mucho más segura que la anterior.
Incrustación de la información con LSB replacement
Supongamos que disponemos de los siguientes valores, correspondientes a un grupo de bytes obtenidos del medio digital en el que queremos ocultar el mensaje:
| 160 | 60 | 53 | 128 | 111 | 43 | 84 | 125 |
Si obtenemos su valor en binario tenemos:
| 10100000 | 00111100 | 00110101 | 10000000 |
| 01101111 | 00101011 | 01010100 | 01111101 |
Supongamos ahora que queremos ocultar un byte, por ejemplo el correspondiente al valor de la letra ‘A’ en codificación ASCII. Este valor corresponde al número 65, cuya representación en binario es la siguiente:
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
Lo haremos sustituyendo el valor del bit menos significativo de cada valor:
| 10100000 | 00111101 | 00110100 | 10000000 |
| 01101110 | 00101010 | 01010100 | 01111101 |
De manera que nos quedarán los siguientes valores:
| 160 | 61 | 52 | 128 | 110 | 42 | 84 | 125 |
En los inicios de la esteganografía en imágenes digitales se pensó erróneamente que esta era la forma más apropiada de esconder información, puesto que modificaba únicamente un bit. Desde un punto de vista intuitivo tiene mucho sentido, puesto que esta técnica nos permite insertar un bit de información modificando el valor del byte lo mínimo posible. Sin embargo esta operación introduce cambios significativos en la distribución estadística de los bytes, lo que la hace muy detectable.
Veamos cómo incrustar un mensaje usando el lenguaje de programación Python. Lo primero que tenemos que hacer es convertir el mensaje en una lista de unos y ceros.
message_bits = []
message = [ord('A')] # message = [65]
for m in message:
message_bits += [ (m>>i)&1 for i in range(8) ]
Si queremos obtener los datos de, por ejemplo, un archivo de texto, bastaría con:
f = open('secret_data.txt', 'r')
message = [ord(b) for b in f.read()]
Una vez disponemos de los bits del mensaje que queremos incrustar, solo tenemos que recorrer los bytes correspondientes al medio en el que queremos incrustar el mensaje (imagen, audio, vídeo, …) e ir modificando su LSB con el bit correspondiente del mensaje.
Supongamos una variable cover que contiene los valores de los bytes
leídos del medio (suficientes bytes como para incrustar todo el mensaje) y
una variable stego de la misma longitud que cover, en la que
guardaremos el estado del medio después de ocultar el mensaje. Entonces:
cover = [ 160, 60, 53, 128, 111, 43, 84, 125 ]
stego = cover.copy()
for i in range(len(message_bits)):
stego[i] = (cover[i] & ~1) | message_bits[i]
>> cover
[160, 60, 53, 128, 111, 43, 84, 125]
>>> stego
[160, 61, 52, 128, 110, 42, 84, 125]
El contenido de la variable cover procederá del medio en el que
queremos incrustar información, que podrá ser una imagen, un archivo
de audio, un vídeo, etc.
Incrustación de la información con LSB matching
El LSB matching es una técnica que, desde el punto de vista del valor del LSB, ofrece los mismos resultados que el LSB replacement. Sin embargo esta ténica no introduce las anomalías estadísticas que introduce el LSB replacement, por lo que es la forma recomendada de incrustar información en el LSB.
Retomemos el ejemplo anterior para ver como se incrustaría información usando LSB matching. Recordemos que usábamos los siguientes valores:
| 160 | 60 | 53 | 128 | 111 | 43 | 84 | 125 |
que en binario corresponden a:
| 10100000 | 00111100 | 00110101 | 10000000 |
| 01101111 | 00101011 | 01010100 | 01111101 |
Para incrustar el mensaje sumemos o restemos 1 aleatoriamente a aquellos píxeles en los que el valor del LSB no coincide con el bit del mensaje que queremos ocultar. Por ejemplo:
| (+0) 10100000 | (+1) 00111101 | (-1) 00110100 | (+0) 10000000 |
| (-1) 01101110 | (+1) 00101100 | (+0) 01010100 | (+0) 01111101 |
En este caso, el resultado es:
| 160 | 61 | 52 | 128 | 110 | 44 | 84 | 125 |
Con esta técnica estamos ocultando un bit en cada byte.
En esteganografía, se toma como referencia el número total de bytes que tiene el medio, disponibles para ocultar información, como el número de bits que se pueden ocultar para una capacidad del 100%. Es decir, incrustando un bit en cada uno de los bytes disponibles. Por lo tanto, diremos que una técnica tiene una capacidad o un payload del 100% si esconde un bit en cada byte. Así, un método que incruste un bit en cada cuatro bytes tendrá una capacidad del 25%, mientras que un método que incruste dos bits en cada byte tendrá una capacidad del 200%. Sin embargo, lo habitual será trabajar con capacidad pequeñas, dado que cuantos más datos se oculten más inseguro (detectable) será el método.
Veamos ahora cómo incrustar un mensaje usando el lenguaje de programación Python. De la misma forma que en el apartado anterior, empezaremos convirtiendo los valores que representan el mensaje en unos y ceros:
message_bits = []
message = [ord('A')] # message = [65]
for m in message:
message_bits += [ (m>>i)&1 for i in range(8) ]
A continuación los incrustaremos en los valores cover. Aunque esta vez
lo haremos usando LSB matching, es decir, sumando o restando 1 aleatoriamente:
import random
cover = [ 160, 60, 53, 128, 111, 43, 84, 125 ]
stego = cover.copy()
for i in range(len(message_bits)):
if cover[i]%2 != message_bits[i]:
stego[i] = cover[i] + random.choice([-1, +1])
>>> cover
[160, 60, 53, 128, 111, 43, 84, 125]
>>> stego
[160, 61, 54, 128, 110, 44, 84, 125]
Es importante tener en cuenta que se podría dar el caso de que la suma de 1 o -1 genere un resultado fuera de rango. Los bytes van de 0 a 255 por lo que no podemos usar valores negativos o valores positivos mayores que 255. Es decir, que al incrustar un mensaje tendremos que controlar que nunca se resta 1 de los valores 0 y que nunca se suma 1 a los valores 255.
Extracción de la información
Para extraer el mensaje únicamente tenemos que leer el LSB de los valores de los bytes correspondientes al medio que contiene el mensaje. El mismo procedimiento es válido para leer datos incrustados con LSB replacement y con LSB matching.
Veamos como realizar esta operación usando Python. Primero extraemos los bits:
message_bits = [ s%2 for s in stego ]
En este caso, la variable stego contiene los valores de los bytes extraídos
del medio.
Ahora tenemos que agrupar los bits de 8 en 8 para formar el valor de los bytes del mensaje original:
message_ex = []
value = 0
for i in range(len(message_bits)):
if i%8==0 and i!=0:
message_ex.append(value)
value = 0
value |= message_bits[i] << i%8
Los peligros del LSB replacement
Hemos comentado que el LSB replacement es inseguro, lo que en esteganografía significa que es detectable. Esto es debido a que la incrustación se realiza de una forma asimétrica, es decir, que no existe la misma probabilidad de incrementar un valor que de decrementarlo.
Cuando sustituimos el LSB de un valor par (un LSB con valor 0) por un bit del mensaje con valor 1, el efecto que se produce es el mismo que el de añadir uno a ese valor. De la misma manera, cuando sustituimos el LSB de un píxel con valor impar (un LSB con valor 1) por un bit del mensaje con valor 0, el efecto que se produce es el mismo que el de restar uno a ese valor. Esta es una operación asimétrica, en el sentido de que nunca se suma 1 a un valor impar y nunca se resta uno a un valor par.
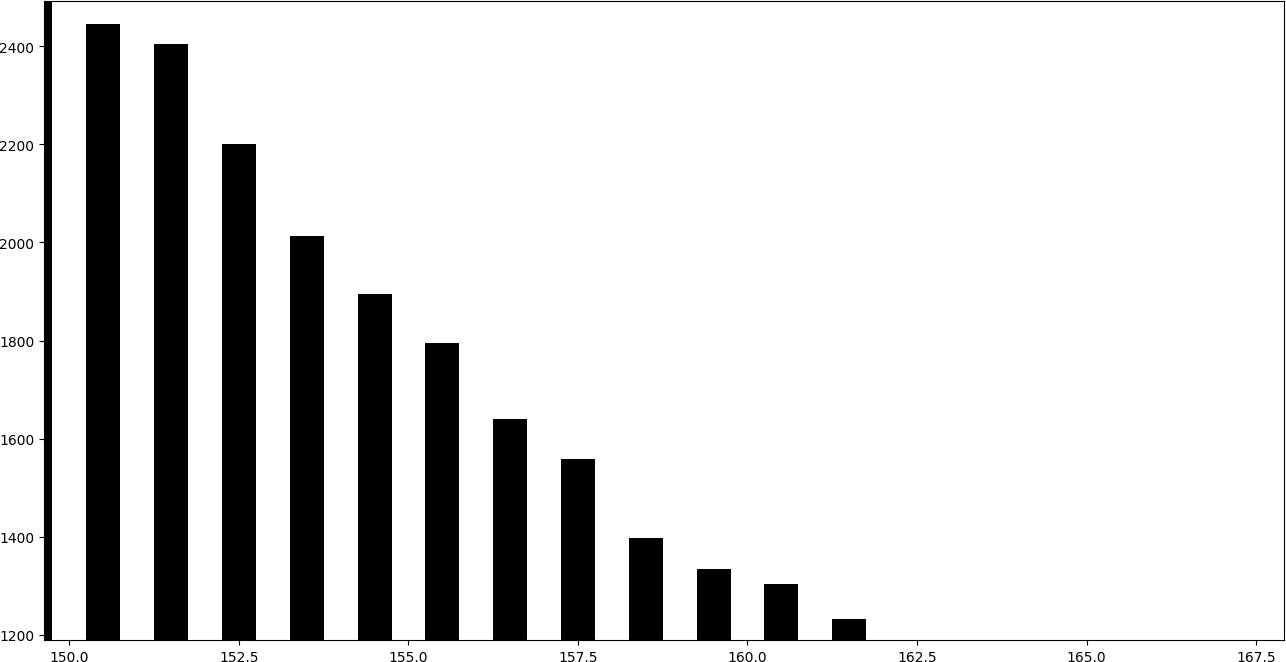
Para ver qué implica incrustar información de esta manera es muy ilustrativo dibujar un histograma de valores. Es decir, un gráfico de barras en el que cada barra representa la cantidad de valores iguales.
La siguiente gráfica corresponde a una imagen que no ha sido alterada usando LSB replacement.
En cambio, la siguiente gráfica corresponde a una imagen a la que se le ha incrustado un mensaje usando LBB replacement.
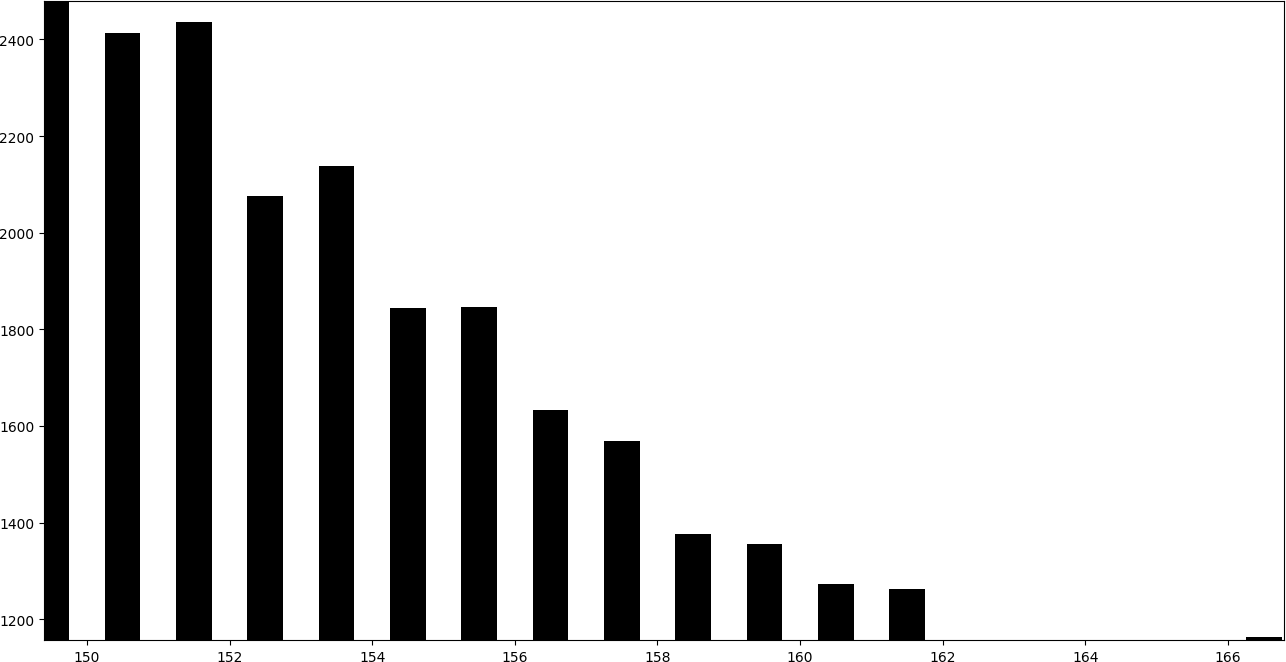
En el histograma se puede apreciar que los pares de barras consecutivos tienden a obtener una altura similar.
Al sumar uno a las barras pares, estas ceden parte de sus valores a la barra posterior, mientra que al restar uno a las barras impares, estas ceden parte de sus valores a la barra anterior. Por ello, los pares de barras consecutivas par-impar tienden a tomar una altura similar.
Existen toda una familia de ataques dedicados a explotar esta anomalía estadística introducida por el LSB replacement. Estos ataques se conocen como ataques estructurales y pueden ser explotados con herramientas de estegoanálisis como Aletheia. En Ataque práctico a esquemas LSB replacement se explica como usar esta herramienta para detectar este tipo de esquemas de esteganografía, usados por muchas herramientas populares como OpenStego y OpenPuff.
Hacia una incrustación más eficiente
Un concepto muy importante en esteganografía es el de eficiencia de la incrustación. Una eficiencia de 1 correspondería a una tècnica de inserción que modificase todos los bytes en los que incrusta un bit. Es decir, una modificación por cada bit insertado.
Sin embargo, las dos técnicas que hemos descrito son más eficientes. Pues, estadísticamente, la mitad de los bytes en los que queremos ocultar información ya tendrán como valor del LSB el bit del mensaje que queremos incrustar, por lo que no será necesario modificarlo. Así pues, estaremos incrustando un bit en cada byte, pero solo estaremos modificando la mitad de los bytes. En consecuencia, la eficiencia de estas técnicas es de 2 bits por modificación.
Aunque pueda sorprender, existen técnicas todavía más eficientes. Técnicas que nos permiten incrustar información con eficiencias muy superiores. Por ejemplo, una incrustación basada en códigos de Hamming nos permite incrustar $p$ bits en $2^p-1$ bytes realizando una sola modificación. Si usásemos, por ejemplo, $p=3$ podríamos incrustar 3 bits en cada bloque de 7 bytes con una sola modificación. Nuestra eficiencia sería en este caso de 3.429.
Existen muchas familias de códigos que nos permiten realizar este tipo de incrustaciones eficientes. Estos temas se tratan con cierto detalle en los siguientes artículos:
Esteganografía LSB en imágenes sin comprimir
Las imágenes sin comprimir suelen representarse como imágenes de mapa de bits (bitmap). Las imágenes de mapa de bits almacenan los valores de los píxeles en una matriz, característica común a la mayoría de las imágenes digitales. Sin embargo, en el contexto de las imágenes sin comprimir, cada píxel en una imagen de mapa de bits está directamente mapeado a un bit en el archivo de la imagen. Para una imagen en escala de grises de 8 bits, cada valor en la matriz representa un byte, correspondiente a un número de 0 a 255, que indica la intensidad del píxel. Un valor de 0 representa el color negro, mientras que un valor de 255 indica el blanco. Por lo tanto, todos los valores intermedios representan los diversos tonos de gris en la imagen.
Sin embargo, lo más habitual es que las imágenes sean en colory y que representen los píxeles con un conjunto de tres bytes: la cantidad de rojo (R), la cantidad de verde (G) y la cantidad de azul (B). Este tipo de representación (RGB) es muy común, aunque también es habitual el RGBA, que usa un byte adicional para almacenar el nivel de transparencia del píxel.
Veamos como podemos leer una imagen usando Python:
import imageio
I = imageio.imread("cover-image.png")
En una imagen en escala de grises nos encontraríamos con algo similar a lo que vemos a continuación:
>>> I.shape
(512, 512)
>>> I[:10, :10]
Array([[155, 155, 155, 154, 155, 149, 156, 153, 158, 154],
[155, 155, 155, 154, 155, 149, 156, 153, 158, 154],
[155, 155, 155, 154, 155, 149, 156, 153, 158, 154],
[155, 155, 155, 154, 155, 149, 156, 153, 158, 154],
[155, 155, 155, 154, 155, 149, 156, 153, 158, 154],
[157, 157, 150, 148, 154, 152, 151, 152, 153, 153],
[153, 153, 157, 151, 153, 155, 151, 148, 152, 155],
[151, 151, 148, 150, 151, 151, 148, 150, 151, 154],
[148, 148, 151, 151, 152, 153, 149, 150, 156, 150],
[148, 148, 151, 151, 147, 147, 148, 150, 154, 146]], dtype=uint8)
Sin embargo, si realizamos la misma operación en una imagen en color, nos encontraremos con tres canales (el R, el G y el B):
>>> I.shape
(512, 512, 3)
>>> I[:10,:10, 0]
Array([[226, 226, 223, 223, 226, 226, 228, 227, 227, 225],
[226, 226, 223, 223, 226, 226, 228, 227, 227, 225],
[226, 226, 223, 223, 226, 226, 228, 227, 227, 225],
[226, 226, 223, 223, 226, 226, 228, 227, 227, 225],
[226, 226, 223, 223, 226, 226, 228, 227, 227, 225],
[227, 227, 227, 222, 226, 228, 226, 230, 225, 228],
[228, 228, 225, 224, 225, 229, 229, 229, 227, 227],
[223, 223, 226, 221, 227, 225, 226, 228, 226, 224],
[225, 225, 224, 224, 225, 224, 229, 225, 226, 225],
[223, 223, 224, 222, 227, 225, 224, 227, 228, 223]], dtype=uint8)
>>> I[:10,:10, 1]
Array([[137, 137, 137, 136, 138, 129, 138, 134, 140, 136],
[137, 137, 137, 136, 138, 129, 138, 134, 140, 136],
[137, 137, 137, 136, 138, 129, 138, 134, 140, 136],
[137, 137, 137, 136, 138, 129, 138, 134, 140, 136],
[137, 137, 137, 136, 138, 129, 138, 134, 140, 136],
[140, 140, 131, 130, 136, 133, 132, 133, 136, 134],
[134, 134, 141, 133, 134, 137, 132, 128, 134, 137],
[133, 133, 129, 132, 131, 133, 129, 131, 131, 137],
[129, 129, 133, 133, 134, 134, 130, 132, 139, 131],
[130, 130, 133, 134, 128, 127, 129, 130, 135, 128]], dtype=uint8)
>>> I[:10,:10, 2]
Array([[125, 125, 133, 128, 120, 116, 123, 124, 127, 119],
[125, 125, 133, 128, 120, 116, 123, 124, 127, 119],
[125, 125, 133, 128, 120, 116, 123, 124, 127, 119],
[125, 125, 133, 128, 120, 116, 123, 124, 127, 119],
[125, 125, 133, 128, 120, 116, 123, 124, 127, 119],
[123, 123, 113, 111, 120, 115, 120, 113, 109, 117],
[119, 119, 116, 115, 125, 112, 116, 105, 113, 120],
[121, 121, 106, 114, 120, 116, 112, 106, 124, 116],
[106, 106, 112, 110, 118, 127, 108, 110, 125, 113],
[104, 104, 109, 117, 102, 109, 108, 115, 120, 104]], dtype=uint8)
Una vez tenemos acceso al array de Numpy que contiene los datos, podemos
incrustar un mensaje usando las técnicas que se han descrito en los
apartados anteriores. Si llamamos Is a nuestro array modificado con el
mensaje oculto, podemos guardar la imagen en Python mediante:
imageio.imwrite("stego-image.png", Is)
Para finalizar, veamos un ejemplo completo en el que guardamos la cadena
"Hello World en una imagen. Primero obtenemos la representación del
mensaje en bits. A continuación obtenemos un vector coverde 128 píxeles
en el que vamos a ocultar el mensaje. Después, modificamos el vector
cover obteniendo el vector stego modificando el LSB de cada
byte para incrustar el bit del mensaje. Finalmente, guardamos la imagen con
los datos modificados.
import imageio
import random
I = imageio.imread("cover-image.png")
message_bits = []
for l in "Hello World":
message_bits += [ (ord(l)>>i)&1 for i in range(8) ]
cover = I[:128, 0, 0]
stego = cover.copy()
for i in range(len(message_bits)):
if cover[i]%2 != message_bits[i]:
if cover[i] == 255:
s = -1
elif cover[i] == 0:
s = +1
else:
s = random.choice([-1, +1])
stego[i] = cover[i] + s
I[:128, 0, 0] = stego
imageio.imwrite("stego-image.png", I)
A continuación, vamos a extraer el mensaje oculto:
import imageio
Is = imageio.imread("stego-image.png")
stego = Is[:128, 0, 0]
message_bits = [ s%2 for s in stego ]
message_ex = []
value = 0
for i in range(len(message_bits)):
if i%8==0 and i!=0:
message_ex.append(value)
value = 0
value |= message_bits[i] << i%8
>>> ''.join([chr(l) for l in message_ex])
'Hello Worlde7<¢'
>>>
Podemos ver algunos caracteres extraños al final de la cadena extraída. Esto es debido a que hemos extraído todos los bits del vector seleccionado, que contiene 128 píxeles, aunque los últimos no se usan. Una herramienta de esteganografía podría evitar el problema indicando la longitud del mensaje en una cabecera también oculta.
Esteganografía LSB en imágenes JPEG
Las imágenes JPEG tienen un funcionamiento bastante más complejo que el de las imágenes de tipo mapa de bits. No vamos a entrar en detalle de cómo funciona todo el proceso de compresión y descompresión que se realiza. El enlace indicado es un buen punto de partida para ampliar información. Sí que realizaremos, sin embargo, una breve descripción del proceso, centrándonos en las partes que nos interesan desde el punto de vista de la esteganografía.
Para comprimir una imagen usando el estándar JPEG, partimos del mapa de bits que representa la imagen. Dividimos dicho mapa de bits en bloques de $8 \times 8$ píxeles y aplicamos la Transformada Discreta del Coseno (DCT) después de restar 128 al valor de los píxeles. Como resultado, obtenemos un nuevo bloque de $8 \times 8$ valores, a los que llamamos coeficientes DCT. Estos valores se dividen por unas matrices predefinidas llamadas matrices de cuantización, redondeando al entero más cercano. Estas matrices están diseñadas para reducir la información en los componentes de alta frecuencia, que son los que peor distingue el ojo humano. Este tipo de operación es una operación con pérdida de información, por lo que una vez comprimida la imagen no se podrá recuperar su estado original. Es el resultado de estos coeficientes DCT cuantizados lo que se almacena en el fichero JPEG, por lo que, desde el punto de vista de la esteganografía, nos interesará ocultar información en dichos coeficientes.
Habitualmente, las librerías de procesamiento de imágenes no proporcionan acceso a los coeficientes DCT, por lo que tendremos que usar una librería especial que nos proporcione dicho acceso. Usaremos el JPEG Toolbox.
Una vez instalada la librería, podemos leer la imagen de la siguiente manera:
import jpeg_toolbox
img = jpeg_toolbox.load('cover-image.jpg')
>>> img['image_height']
512
>>> img['image_width']
512
>>> img['image_components']
3
De la información que nos proporciona esta librería, estaremos interesados principalmente en el acceso a los coeficientes DCT. Veamos cómo acceder a los tres canales disponibles:
>>> img['coef_arrays'][0].shape
(512, 512)
>>> img['coef_arrays'][0]
array([[86., 2., 2., ..., 0., -1., 0.],
[ 4., 0., 0., ..., -1., 0., -1.],
[-3., 0., -1., ..., 0., 0., 0.],
...,
[ 1., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.]])
>>> img['coef_arrays'][1]
array([[-60., 3., 0., ..., 0., 0., 0.],
[ 4., 0., 0., ..., 0., 0., 0.],
[ -1., 0., 0., ..., 0., 0., 0.],
...,
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.]])
>>> img['coef_arrays'][2]
array([[124., -3., 1., ..., 0., 0., 0.],
[ -3., 0., 0., ..., 0., 0., 0.],
[ 1., 0., 0., ..., 0., 0., 0.],
...,
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.]])
Debido a la cuantización, la cantidad de coeficientes con valor cero suele ser muy grande. Más, cuanto mayor es el nivel de compresión aplicado. No es buena idea ocultar información en esos coeficientes, puesto que esto podría ser sospechoso. El primer problema que nos encontraríamos es que el tamaño del fichero crecería. Esto es debido a que la forma en la que JPEG almacena los datos evita guardar los ceros, y si ocultamos información en esos coeficientes, el algoritmo JPEG tendría que almacenarlos. Adicionalmente, la existencia de valores en coeficientes en los que, debido a la cuantización, debería haber ceros, también sería algo muy sospechoso.
Así pues, en esteganografía JPEG, es habitual evitar modificar los coeficientes con valor cero.
Una vez hemos modificado los coeficientes DCT y hemos ocultado el mensaje, podemos guardar la nueva imagen de la siguiente manera:
>>> jpeg_toolbox.save(img, 'stego-image.jpg')
Esquivar los ceros para ocultar información tiene cierta complejidad, pues si simplemente los ignoramos, el receptor del mensaje tendrá que hacer lo mismo. Pero esto implica que no podremos hacer ninguna operación de incrustado que genere un nuevo cero, puesto que el receptor no sabría que ese cero no lo tiene que ignorar. Intentar no generar nuevos ceros podría llevar a introducir serias anomalías estadísticas que harían nuestro sistema muy detectable. Existen diferentes técnicas para lidiar con este tipo de problemas, aunque no las vamos a tratar en este artículo. Analizaremos el problema con detalle en artículos posteriores.
A continuación vamos a ver un ejemplo completo en el que ocultaremos la cadena
"Hello World". Úsaremos únicamente el coeficiente DC, que es como llamamos
al coeficiente de arriba a la izquierda de cada bloque de $8 \times 8$. De esta
manera no afectaremos a los ceros y el receptor sabrá qué coeficientes leer.
Primero representamos el mensaje a incrustar como una lista de bits. A
continuación extraemos el coefficiente de la esquina superior izquierda de cada
bloque de $8 \times 8$. Esto lo hacemos usando la indexación de Numpy
[::8,::8]. Para el ejemplo, únicamente extraemos datos del primer canal.
Puesto que los datos extraídos estan representados como una matriz de dos
dimensiones, usamos la función flatten() para representarlos como un
vector. A continuación incrustamos el mensaje y representamos de nuevo los datos
del vector como matriz de dos dimensiones. Finalemente, guardamos los datos en
un fichero JPEG.
import jpeg_toolbox
img = jpeg_toolbox.load('cover-image.jpg')
message_bits = []
for l in "Hello World":
message_bits += [ (ord(l)>>i)&1 for i in range(8) ]
cover = img['coef_arrays'][0][::8,::8]
shape = cover.shape
cover = cover.flatten()
stego = cover.copy()
for i in range(len(message_bits)):
if cover[i]%2 != message_bits[i]:
stego[i] = cover[i] + random.choice([-1, +1])
img['coef_arrays'][0][::8,::8] = stego.reshape(shape)
jpeg_toolbox.save(img, 'stego-image.jpg')
A continuación, vamos a extraer el mensaje oculto:
import jpeg_toolbox
img = jpeg_toolbox.load('stego-image.jpg')
stego = img['coef_arrays'][0][::8,::8].flatten()
message_bits = [ int(s)%2 for s in stego ]
message_ex = []
value = 0
for i in range(len(message_bits)):
if i%8==0 and i!=0:
message_ex.append(value)
value = 0
value |= message_bits[i] << i%8
>>> ''.join([chr(l) for l in message_ex])[:20]
'Hello World\x84iî\x94Ïøó¿Ø'
Igual que en el caso anterior, podemos ver algunos caracteres extraños al final de la cadena extraída, debido a que hemos extraído bits que no se usan.
Esteganografía LSB en ficheros de audio WAV
Los archivos de audio WAV (ver formato WAV) son ficheros que almacenan las muestras que forman el sonido sin usar compresión con pérdida, como en el caso de otros formatos como MP3.
De manera similar a como hemos hecho con las imágenes, podemos leer las muestras que forman el sonido y modificar su LSB para ocultar información.
Python nos proporciona un módulo que nos permite leer y escribir las
muestras de audio de forma sencilla: el módulo wav.
Podemos leer los frames de la siguiente manera:
cover_wav = wave.open("cover-sound.wav", mode='rb')
frames = bytearray(cover_wav.readframes(cover.getnframes()))
Y podemos modificarlos y guardarlos en un nuevo archivo de forma igualmente sencilla. Por ejemplo, sumemos una unidad a la primera muestra y guardemos el archivo modificado:
frames[0] += 1
stego_wav = with wave.open('stego-sound.wav', 'wb')
stego_wav.setparams(cover_wav.getparams())
stego_wav.writeframes(bytes(frames))
El proceso es bastante sencillo. Ahora, como en los casos anteriores vamos
a ver un ejemplo completo en el que ocultaremos la cadena Hello World.
import wave
import random
cover_wav = wave.open("cover-sound.wav", mode='rb')
frames = bytearray(cover_wav.readframes(cover_wav.getnframes()))
message_bits = []
for l in "Hello World":
message_bits += [ (ord(l)>>i)&1 for i in range(8) ]
j = 0
for i in range(0, len(frames), 2):
if frames[i]%2 != message_bits[j]:
if frames[i] == 255:
s = -1
elif frames[i] == 0:
s = +1
else:
s = random.choice([-1, +1])
frames[i] = frames[i] + s
j += 1
if j>=len(message_bits):
break
stego_wav = wave.open('stego-sound.wav', 'wb')
stego_wav.setparams(cover_wav.getparams())
stego_wav.writeframes(bytes(frames))
cover_wav.close()
stego_wav.close()
Conviene darse cuenta de que solo estamos modificando uno de cada dos bytes. El formato WAV normalmente almacena las muestras con precisión de 16 bits, por lo que solo queremos modificar el byte que representa los bits de menos peso.
A continuación, vamos a extraer el mensaje oculto:
import wave
cover_wav = wave.open("stego-sound.wav", mode='rb')
frames = bytearray(cover_wav.readframes(cover_wav.getnframes()))
message_ex = []
value = 0
j = 0
for i in range(0, len(frames), 2):
msg_bit = frames[i]%2
if j%8==0 and j!=0:
message_ex.append(value)
value = 0
value |= msg_bit << j%8
j+=1
>>> ''.join([chr(l) for l in message_ex])[:20]
Hello World¡GhÓ
Igual que en los casos anteriores, podemos ver algunos caracteres extraños al final de la cadena extraída, debido a que hemos extraído bits que no se usan.