An information hiding technique based on binary Hamming codes is presented below.
Introduction
In steganography we say that the embedding efficiency is 1 when we need to make a modification every time we embed a bit. However, when we hide information in the LSB (see LSB steganography in images and audio) the efficiency of the insertion is 2. This is so because, statistically, half of the bytes in which we want to hide information will already have the LSB value of the bit of the message that we want to embed. Therefore, it will not be necessary to modify them. Thus, we will be embedding a bit in each byte, but we will only be modifying half of the bytes. Consequently, the efficiency will be 2 bits per modification.
This efficiency can be easily improved with a simple trick. Let’s see how it works.
We are going to hide information in groups of three bytes:
| A | B | C |
and we are going to use this formula to hide the first bit:
and this formula to hide the second one:
Here $LSB()$ refers to the least significant bit of the pixel and $\oplus$ to an XOR operation.
Applying this method is very simple. If $M_1$ and $M_2$ already have the values we want to hide, we don’t have to do anything. If none of the values of $M_1$ and $M_2$ match, we will change the LSB of $B$. If $M_1$ matches but $M_2$ does not, we will change the LSB of $C$ and if $M_2$ matches but $M_1$ does not, we will change the value of $A$. With this simple technique we can hide two bits by modifying only one.
Let’s see an example. We have the following pixels:
| 10010100 | 10010101 | 10010111 |
If we want to hide $00$ a possible result is:
| (+1) 10010101 | 10010101 | 10010111 |
If we want to hide $01$, an option will be:
| 10010100 | (-1) 10010100 | 10010111 |
If we want to hide $10$, we don’t have to make any changes:
| 10010100 | 10010101 | 10010111 |
And finally, if we want to hide $11$, a possible result will be:
| 10010100 | 10010101 | (-1) 10010110 |
There are four options $00$, $01$, $10$ and $11$. For one out of four options, no modification will be necessary, while for the other three we will modify a single bit. Therefore, we will modify a bit every 3/4 of the cases. Since each of these modifications allows us to embed two bits, we have an efficiency of $\frac{2}{3/4}=2.66$. This efficiency is higher than that of LSB steganography, which was $2$.
Binary Hamming Codes
The idea proposed in the previous section can be generalized using a technique known as matrix embedding using Hamming codes. This technique allows us to hide $p$ bits in a block of $2^p-1$ bits by modifying a single bit.
The first thing we are going to need is a matrix that contains all the combinations of binary vectors of $p$ elements, except the vector of zeros. For example, if we want to use $p=3$, a possible matrix would be the following:
To hide $p$ bits we need a group of $2^p-1$ bits. We will get this group from the digital media in which we want to hide the information. We will call it cover vector, denoted by $c$.
We can calculate the message that “naturally” hides a vector cover by performing the following operation:
It is important to keep in mind that we work with bits, that is, that all the operations we perform are modulo 2 operations.
Although it may be the case that the message $m$ matches the bits we want to embed, it will not always happen. In order to properly modify the vector $c$ to hide our message, the first thing we will do is subtract the message $m$ that we want to hide from $Mc$:
The position of the vector $v$ in the matrix $M$ will tell us which bit of $c$ we have to modify (obtaining the stego vector $s$) so that when performing the extraction operation $Ms$ we obtain the message we want to hide.
Let’s see a simple example with $p=3$ in which we are going to hide the message $m=(1,1,0)$.
Since $p=3$ we will need to hide our message in groups of $2^p-1=7$ bits, so for each embedding we will need a 7-bit cover $c$ vector. We will obtain the vector from the digital media and we will keep its LSB.
Suppose the bytes extracted from the media are as follows:
| 11011010 | 11011011 | 11011011 | 11011010 |
| 11011011 | 11011010 | 11011010 |
We get the LSBs:
| 0 | 1 | 1 | 0 | 1 | 0 | 0 |
So our vector $c$ will be:
We calculate the message that hides this vector:
But this is not the message we want to hide, since we want to hide $m=(1,1,0)$. So we need to figure out how to modify $c$ so that the result of the operation hides our message. That is, we need to get the stego version $s$ of our vector $c$ so that $m = Mc = (1, 1, 0)$.
First we will have to perform the operation $Mc-m$ to locate the position of $c$ that we have to modify to obtain $s$.
which corresponds to the second column of $M$:
This means that we have to change the second bit of $c$ to get the stego vector $s$.
In this way, the extract operation will result in our message:
At this point, we just need to apply this modification to the initial value of the bytes extracted from the media. That is, we convert:
| 11011010 | 11011011 | 11011011 | 11011010 |
| 11011011 | 11011010 | 11011010 |
into:
| 11011010 | 11011010(-1) | 11011011 | 11011010 |
| 11011011 | 11011010 | 11011010 |
Although we have performed a $-1$ operation, a $+1$ operation would also have worked for us, since what we are interested in is the value of the LSB:
| 11011010 | 11011100(+1) | 11011011 | 11011010 |
| 11011011 | 11011010 | 11011010 |
Efficiency
The bigger $p$ is, the more information we can hide with fewer modifications. But if we use a too large $p$ we will find that the groups are so large that we quickly run out of bytes in which to hide information. For example, in a 512x512 pixel image we can hide 18 bits by modifying a single bit. However, we can no longer hide anything else. It is therefore convenient to select a suitable $p$, which allows us to hide information without greatly modifying the media, but which at the same time offers us an acceptable capacity.
We are interested in taking into account two parameters. The first is the payload, that is, what percentage of information can we store per modified byte. We can calculate this with the following formula:
For example, if we use $p=3$, we will need groups of $2^3-1=7$ values. Which gives us a capacity of $0.429$ bits per byte (pixel, audio sample, etc).
The next parameter we are interested in is the efficiency of the insertion, which we can calculate as:
Continuing with our example, the efficiency for $p=3$ is $3.429$. Superior to our initial example, which had an efficiency of $2.66$.
In the following graph we can see the relationship between payload and efficiency. Actually, for better graphical representation, the inverse of payload ($\alpha^{-1}$) is used.
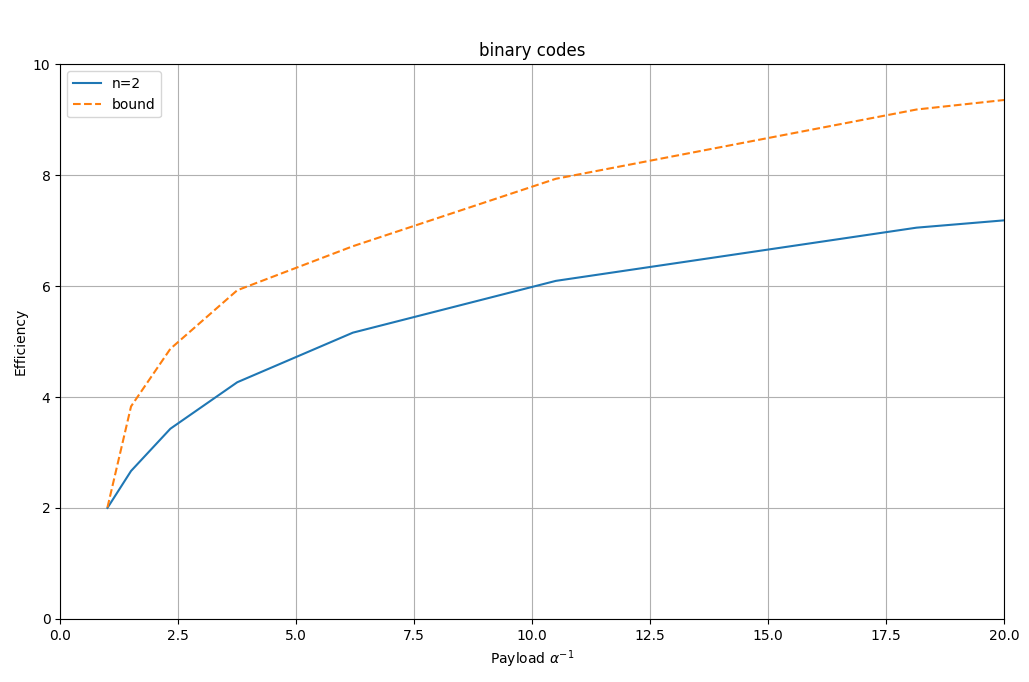
As you can see in the graph, the highest efficiency is achieved with very small payloads (very high $\alpha^{-1}$ values).
In the graph you can also see the theoretical limit for binary codes. As can be seen, these codes do not reach the theoretical capacity.
Example using Python
Let us now see how to perform these operations using the Python programming language.
The first thing we need is the array $M$:
import numpy as np
M = np.array([
[0, 0, 0, 1, 1, 1, 1],
[0, 1, 1, 0, 0, 1, 1],
[1, 0, 1, 0, 1, 0, 1]
])
To embed the message $m$ in the vector cover $c$ we only have to find the position of $Mc-m$ in the matrix $M$ and modify it:
def embed(M, c, m):
s = c.copy()
col_to_find = (M.dot(c)-m)%2
position = 0
for v in M.T:
if np.array_equal(v, col_to_find):
s[position] = (s[position] + 1) % 2
break
position += 1
return s
To extract the embedded message, just perform the $Ms$ operation:
def extract(M, s):
return M.dot(s)%2
Let’s repeat the previous example, now using Python:
m = [1, 1, 0]
c = np.array([
0b11011010, 0b11011011, 0b11011011, 0b11011010,
0b11011011, 0b11011010, 0b11011010
])%2
s = embed(M, c, m)
new_m = extract(M, s)
>>> new_m
array([1, 1, 0])
Python implementation
A full implementation, including message encoding and decoding, before and after embedding, is provided on GitHub link.
Here is an example where we embed data into an image:
import imageio
cover = imageio.imread("image.png")
message = "Hello World".encode('utf8')
hc = HC(3)
stego = cover.copy()
stego[:,:,0] = hc.embed(cover[:,:,0], message)
imageio.imsave("stego.png", stego)
stego = imageio.imread("stego.png")
extracted_message = hc.extract(stego[:,:,0])
print("Extracted message:", extracted_message.decode())
References
- Fridrich, J. (2009). Steganography in Digital Media: Principles, Algorithms, and Applications. Cambridge University Press.